Hi, 我是洪致知,一名软件工程师,坚定不移热爱技术,平时喜欢捣鼓一些小创意,有很多理想,也有点理想主义。
CSDN: 我要去腾讯

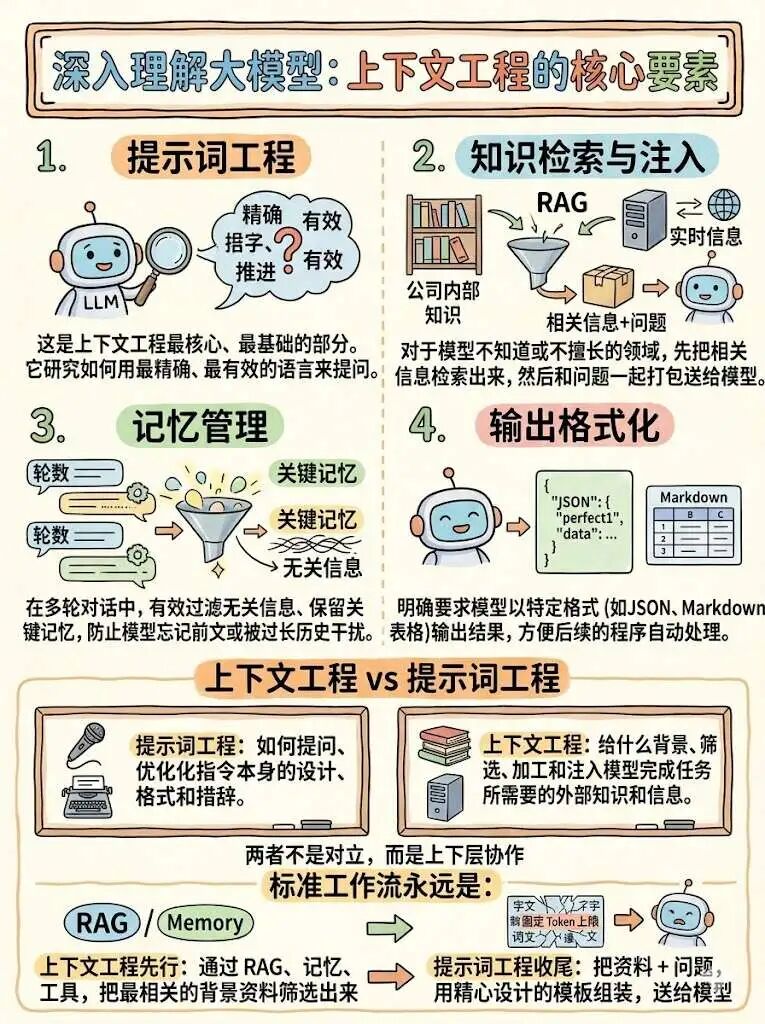
很多人把“上下文”简单理解成提示词或 RAG。这个理解不算错,但不完整。
更准确地说,上下文工程是一套系统化的方法:持续构建、管理、筛选、注入任务相关信息,让大模型在有限预算里稳定输出。
可以抽象为:
Context = System Prompt + User Input + 历史对话 + 工具结果 + 检索内容 + 长期记忆
模型在当前轮次看到的所有信息,决定了它能否做出正确决策。
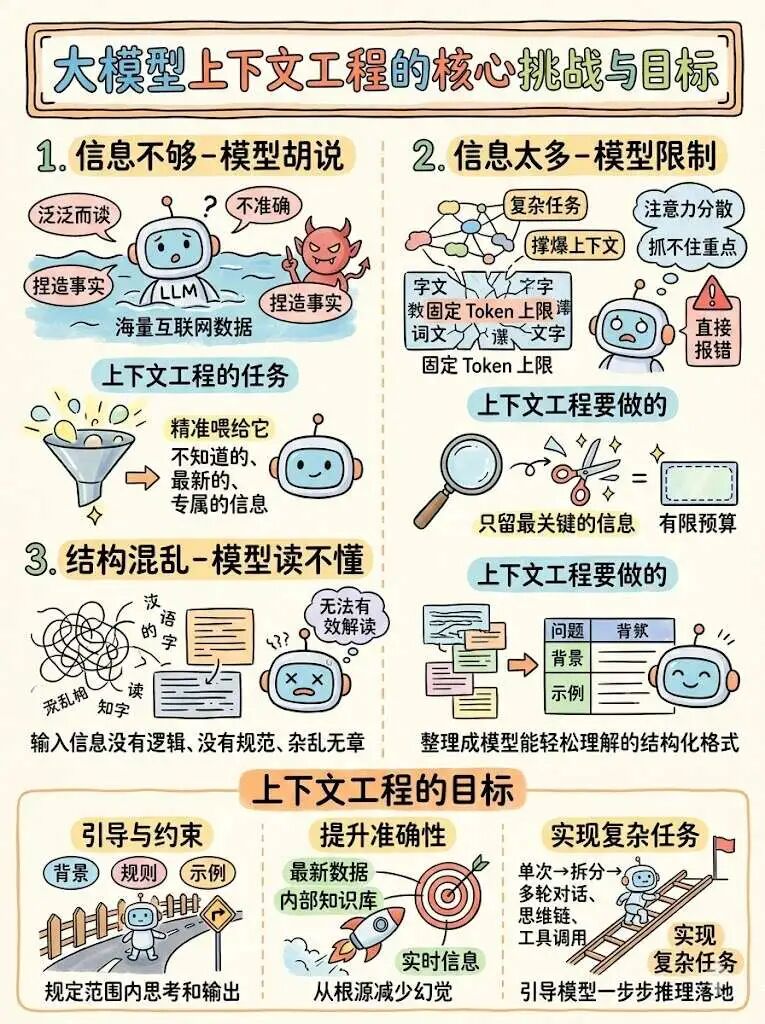
模型训练数据不是实时和专属的。要通过外部知识注入,把最新、准确、任务相关的信息喂给模型。
模型有固定 token 上限。任务越复杂,越容易超限。需要在预算内做选择、压缩、截断。
输入若杂乱无序,模型难以理解。要把数据整理成结构化、可解释、可执行的格式。
标准流程通常是:
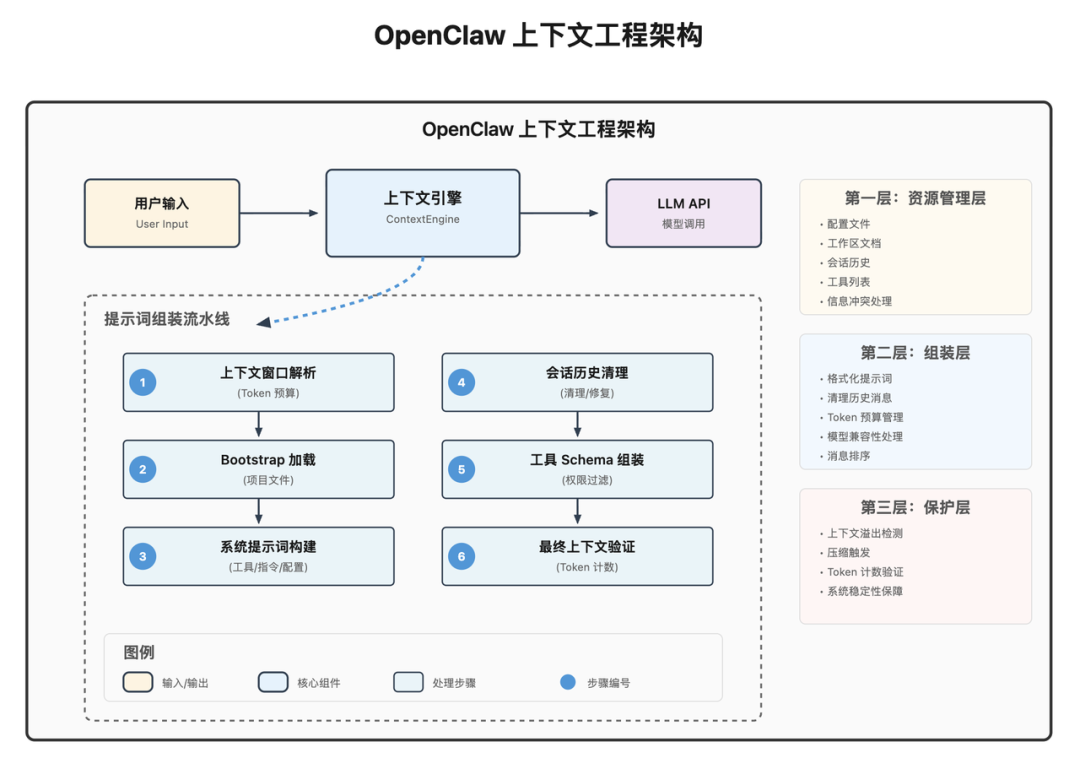
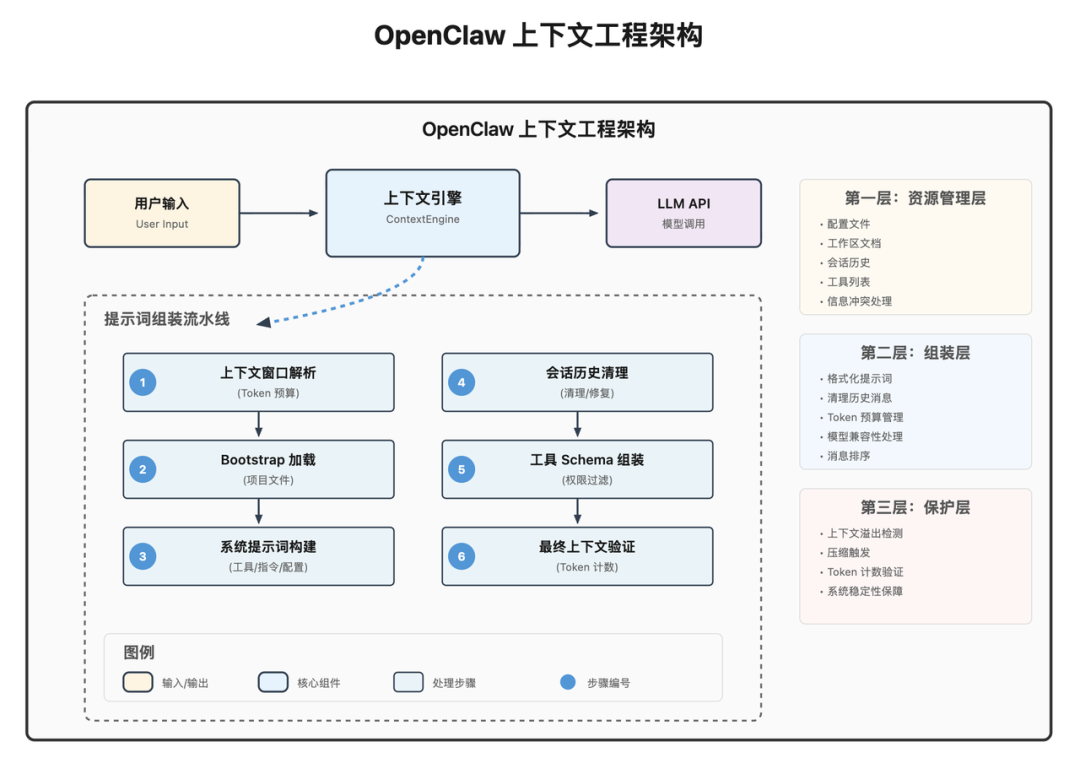
OpenClaw 采用流水线式设计,按职责可分为三层:
负责管理上下文来源与冲突处理,包括:
AGENTS.md、TOOLS.md)负责把信息按固定顺序和格式装配,并处理:
负责稳定性与安全性:
OpenClaw 定义了可插拔的上下文引擎接口,使默认实现可用、定制实现可扩展。
典型流程如下。
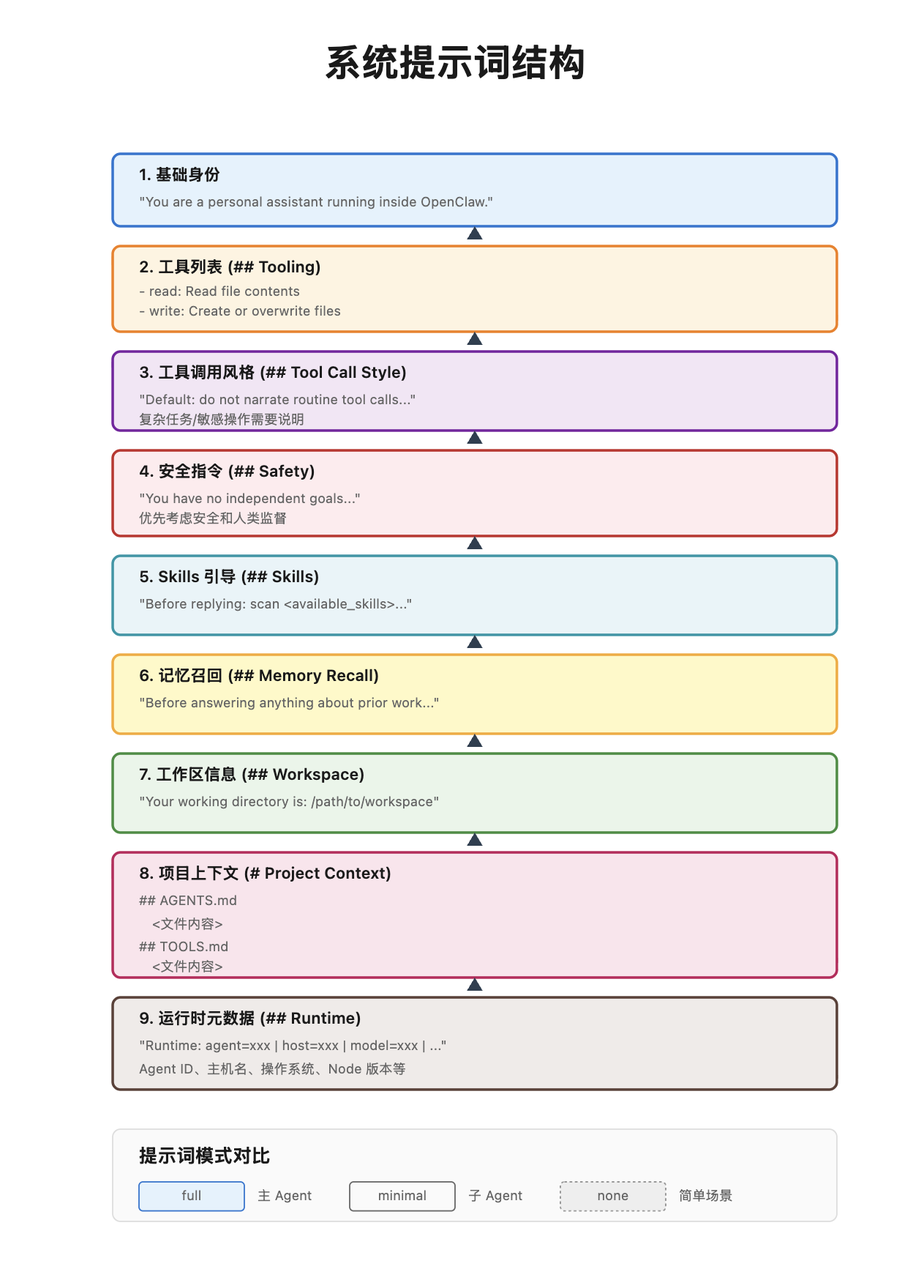
系统提示词会定义 Agent 的身份、能力边界、可用工具和行为规则,核心包括:
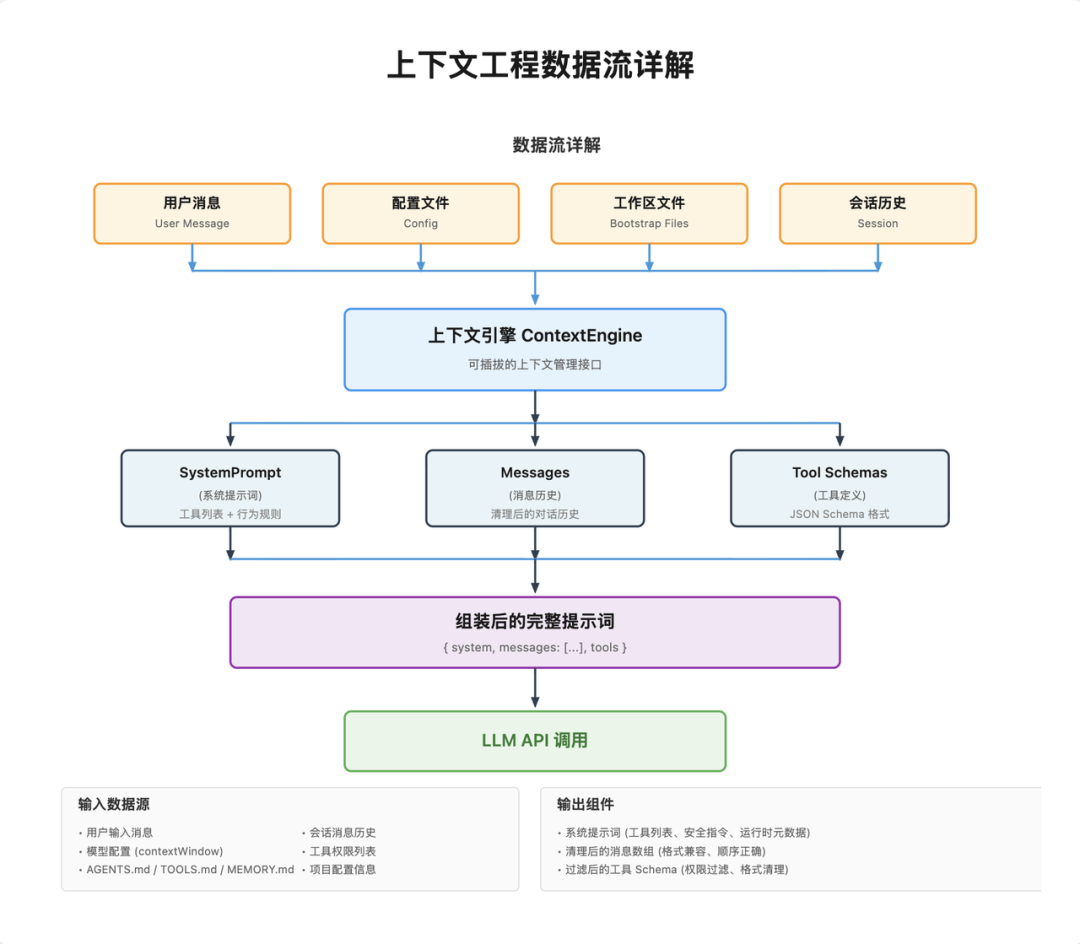
通过工作区文件注入项目级上下文,常见文件:
AGENTS.mdTOOLS.mdMEMORY.md / memory.mdSOUL.mdIDENTITY.mdUSER.mdHEARTBEAT.mdBOOTSTRAP.md并且支持:
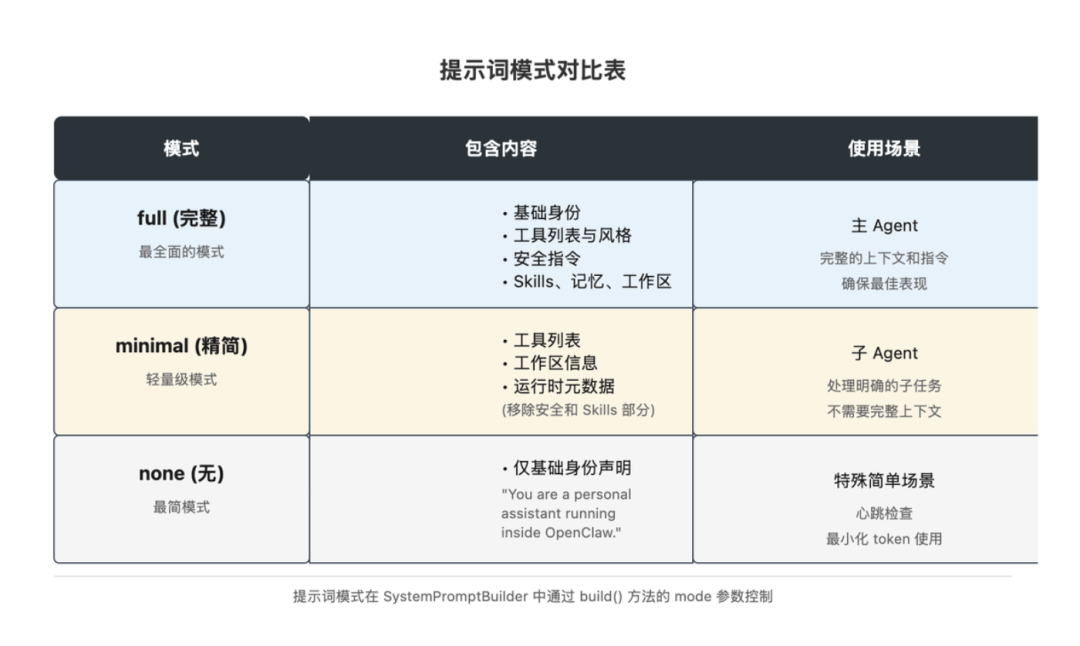
full / lightweight / none 三种上下文模式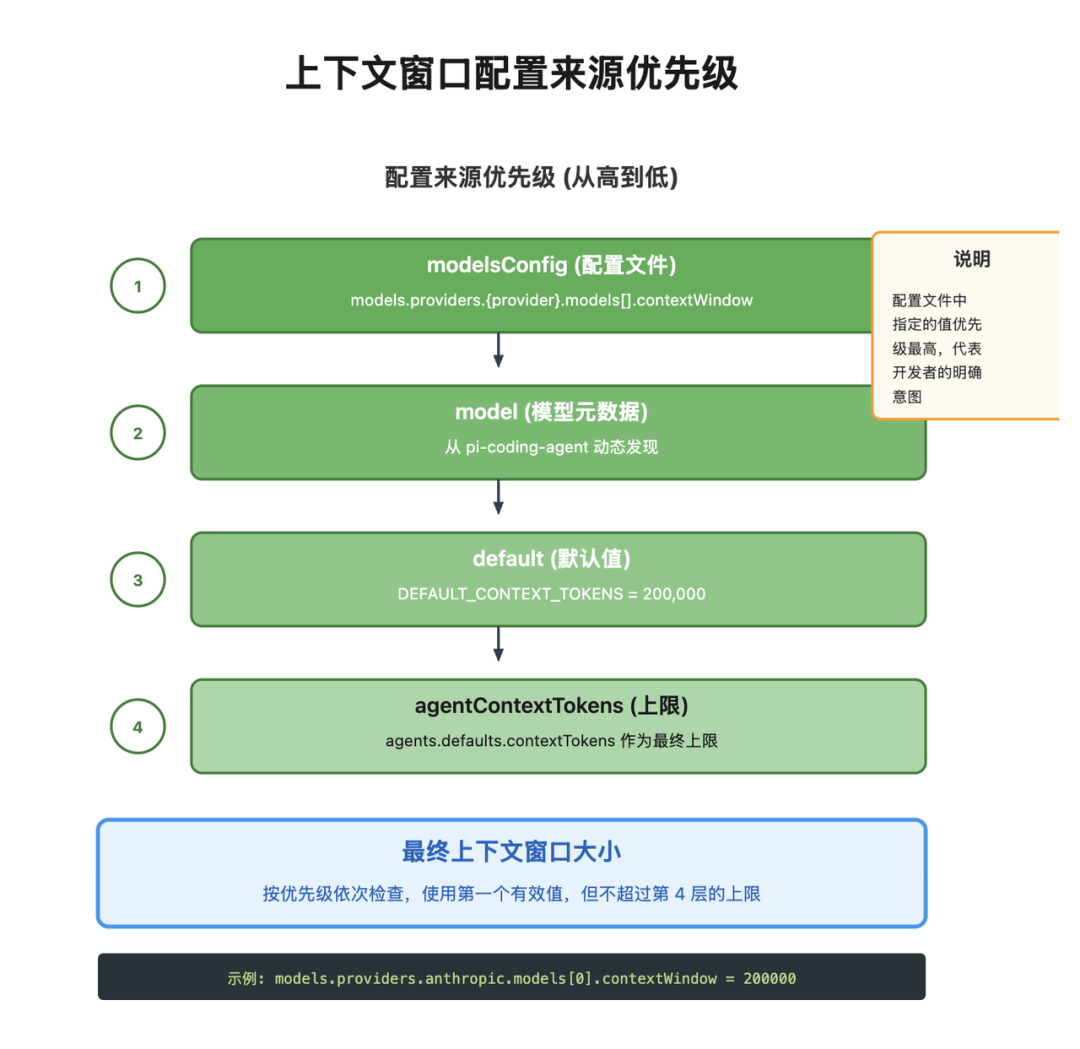
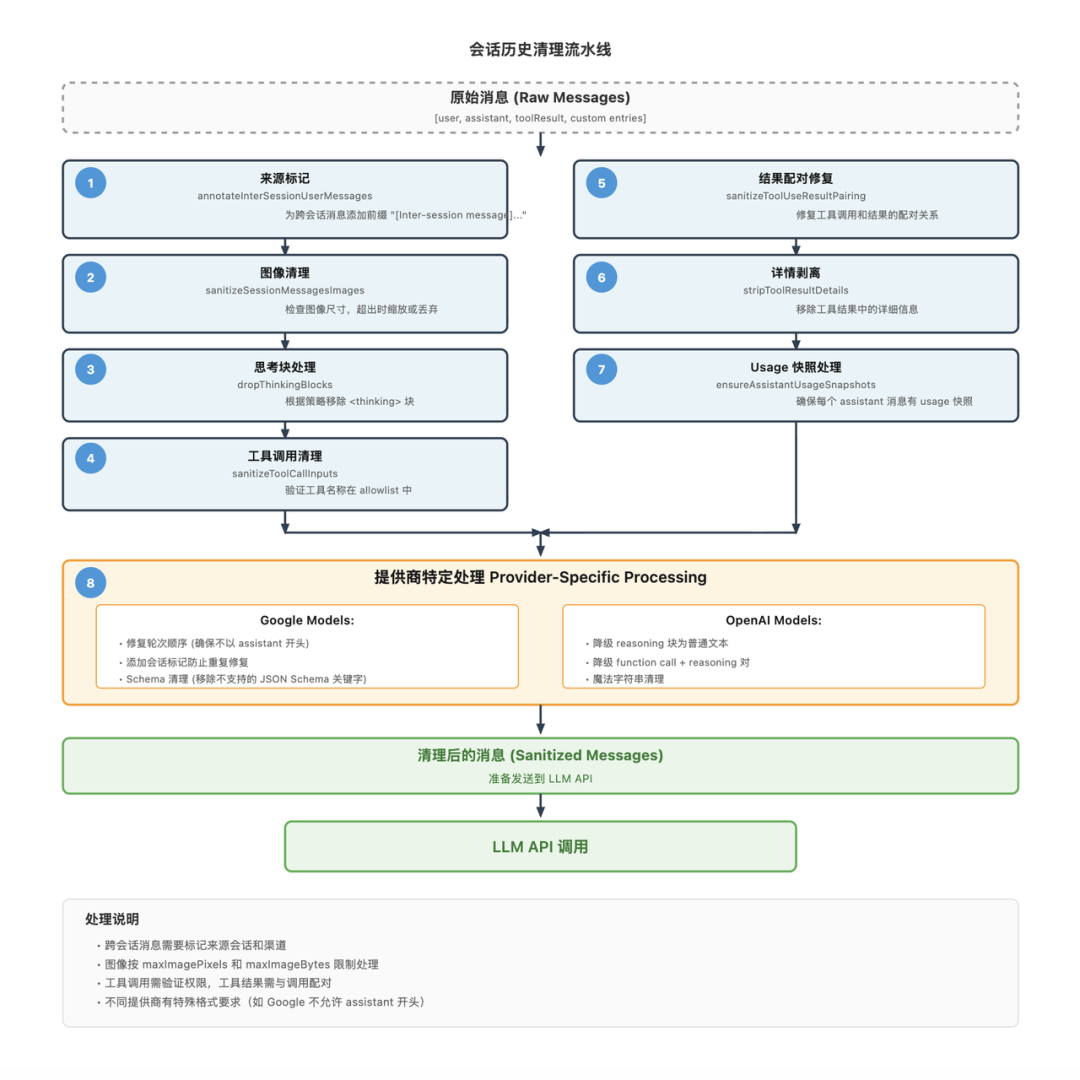
历史消息不能直接复用,需要清洗与修复:

组装后还要做预算与格式验证:

OpenClaw 的上下文窗口值按优先级确定:
contextWindowagents.defaults.contextTokens)保护阈值通常包括:
这套机制用于避免误配置导致的 OOM 或频繁溢出。
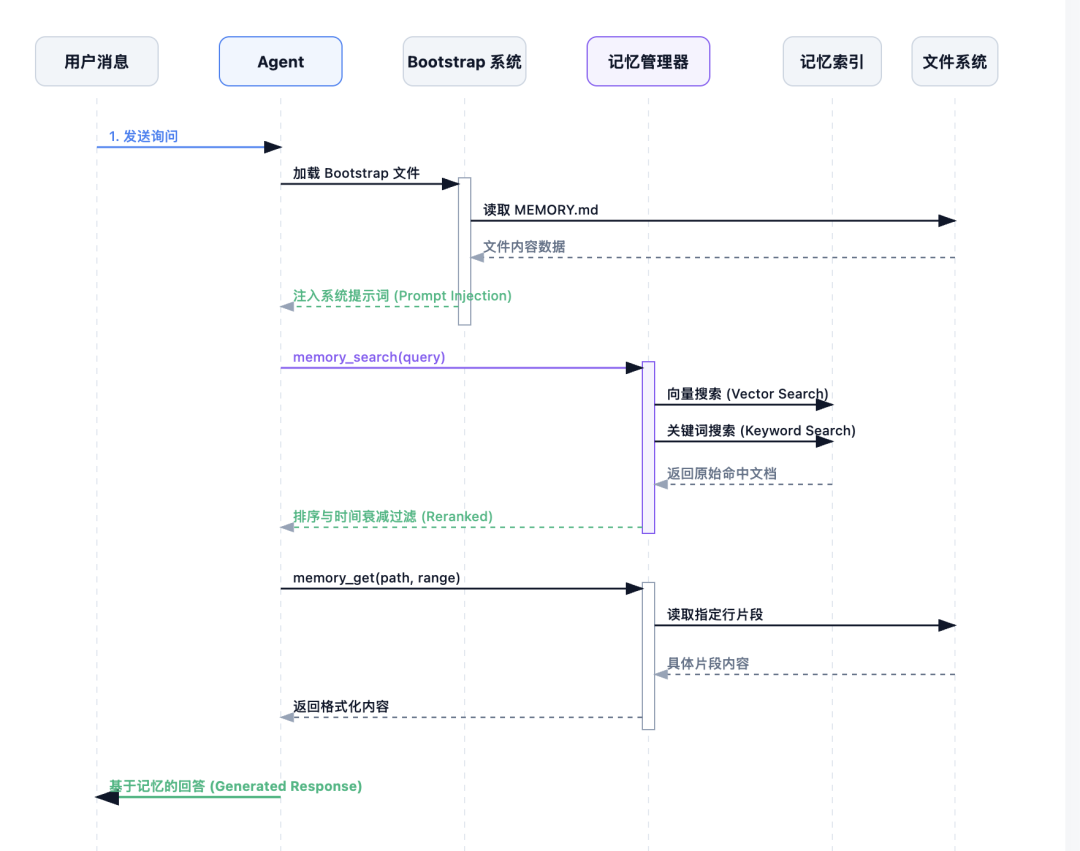
记忆并不是“一股脑塞进上下文”,而是“持久化存储 + 按需检索”。
MEMORY.md:长期记忆(约定、决策、持久事实)memory/YYYY-MM-DD.md:每日记忆(当天过程、临时讨论)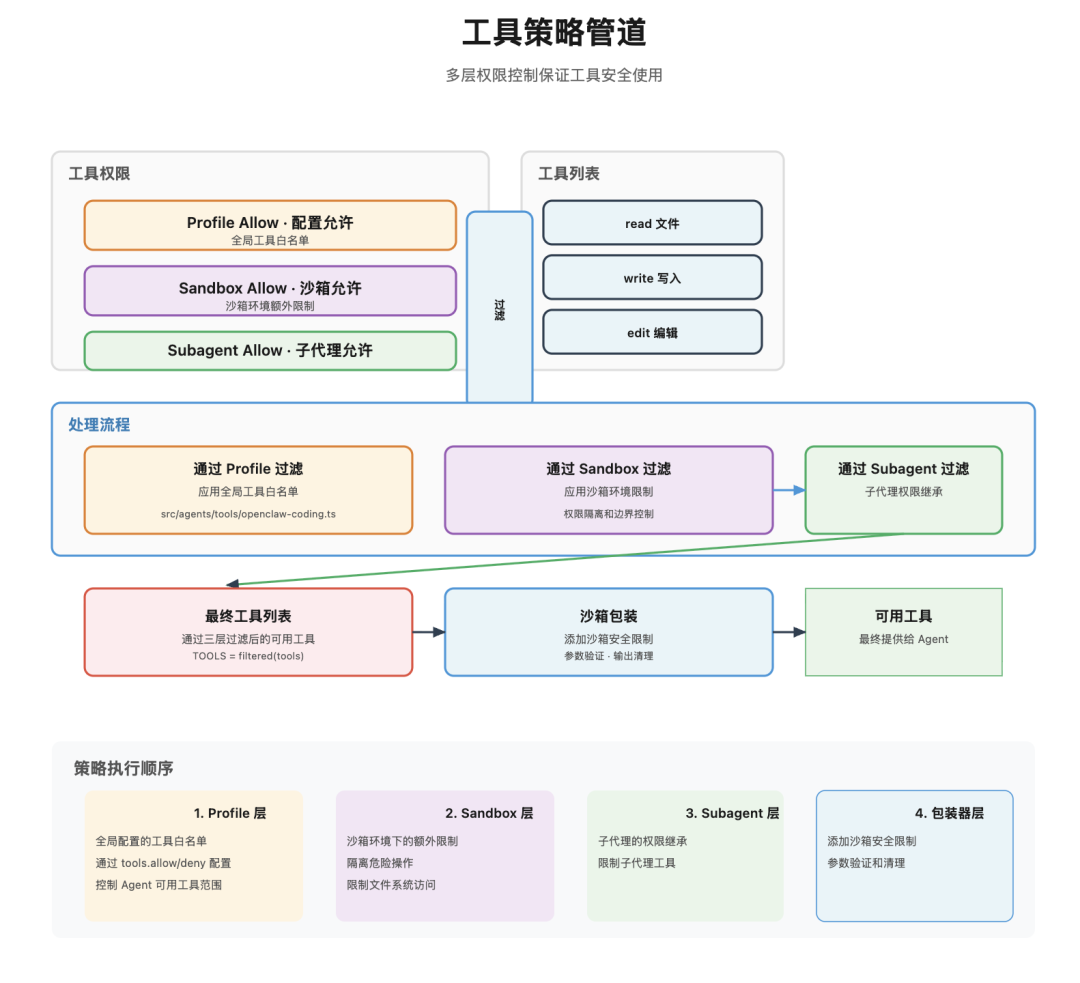
系统会把记忆切块后构建索引,检索时采用混合检索:
常见做法还包括:
MEMORY.md)目标是在不爆 token 的前提下,保留“长期一致性 + 近期相关性”。
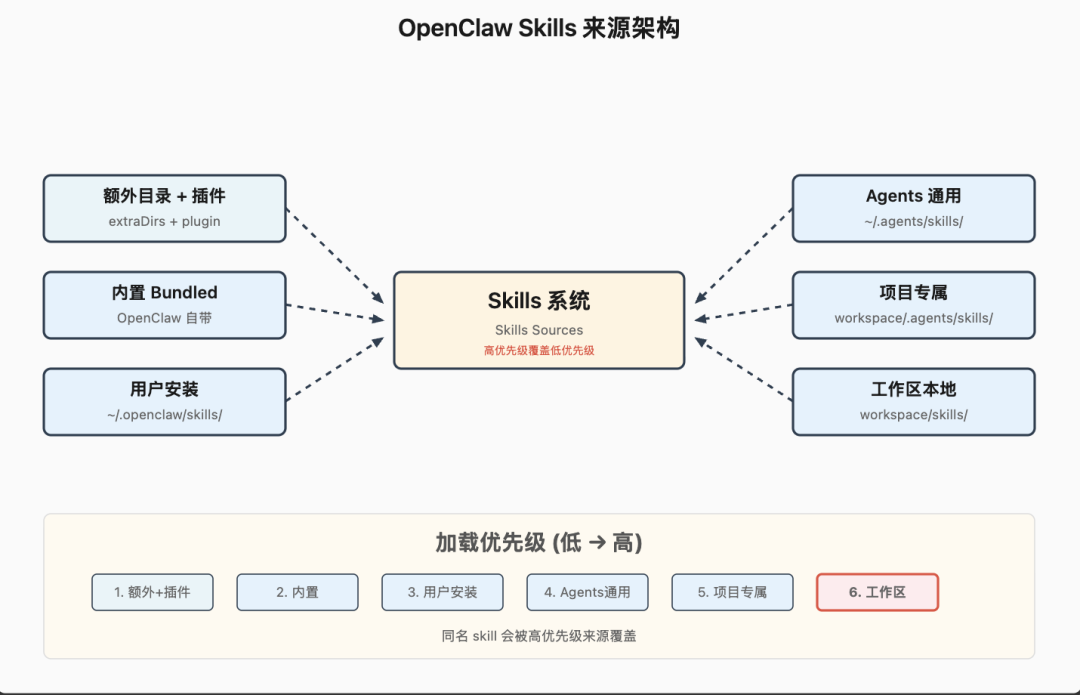
工具来源可来自核心、插件、渠道,但不会全量注入。系统会按策略筛选:
最终只把“当前可用且允许调用”的工具描述写入系统提示词。
Skills 来自内置、用户、插件、项目等多源,按优先级合并去重。并在 token 不足时降级展示格式,确保在预算内保留最关键的 skill 信息。
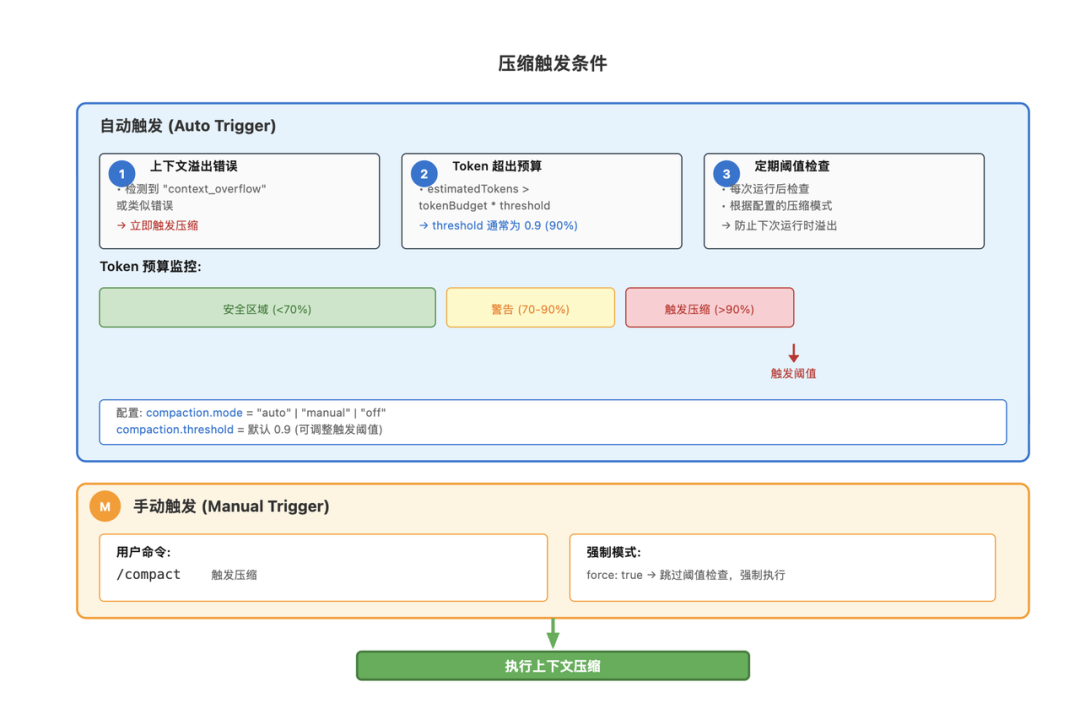
长期会话一定会触发压缩,典型触发方式:
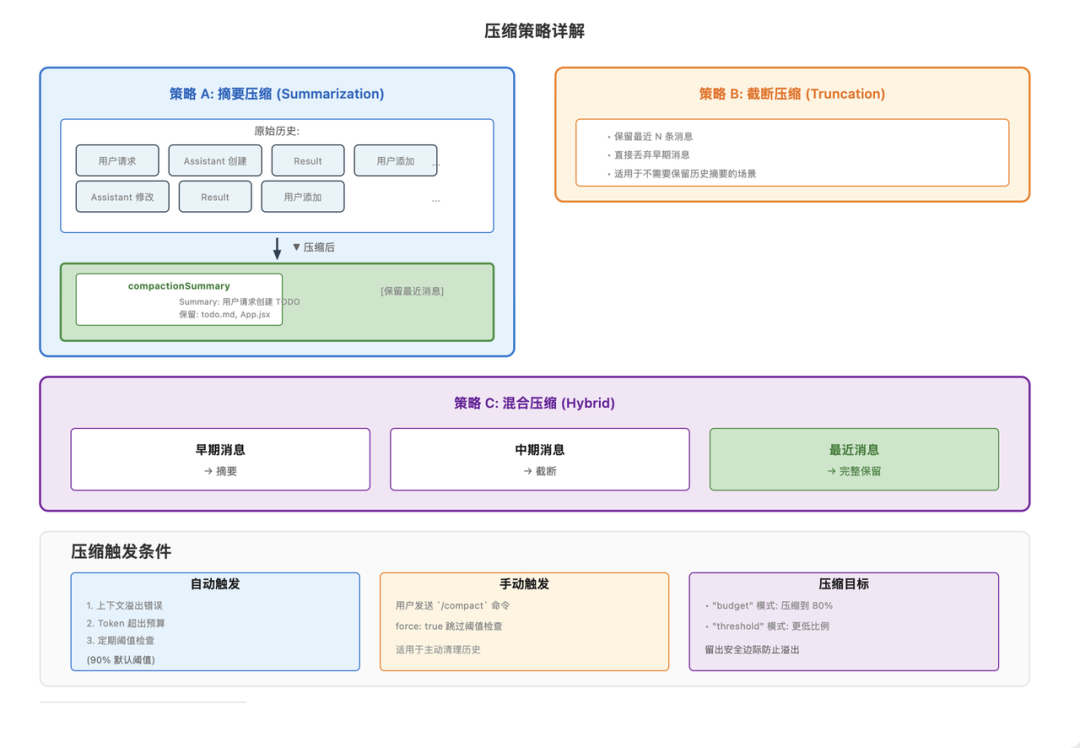
压缩策略分三级:
执行流程通常是:
上下文引擎接口覆盖完整生命周期:
bootstrapingest / ingestBatchassemblecompactafterTurnprepareSubagentSpawn / onSubagentEndeddispose默认传统引擎保持向后兼容:多数方法透传或空实现,仅在压缩阶段委托到既有逻辑。这样可以让团队逐步替换成更智能的上下文引擎,而不必一次性重写系统。
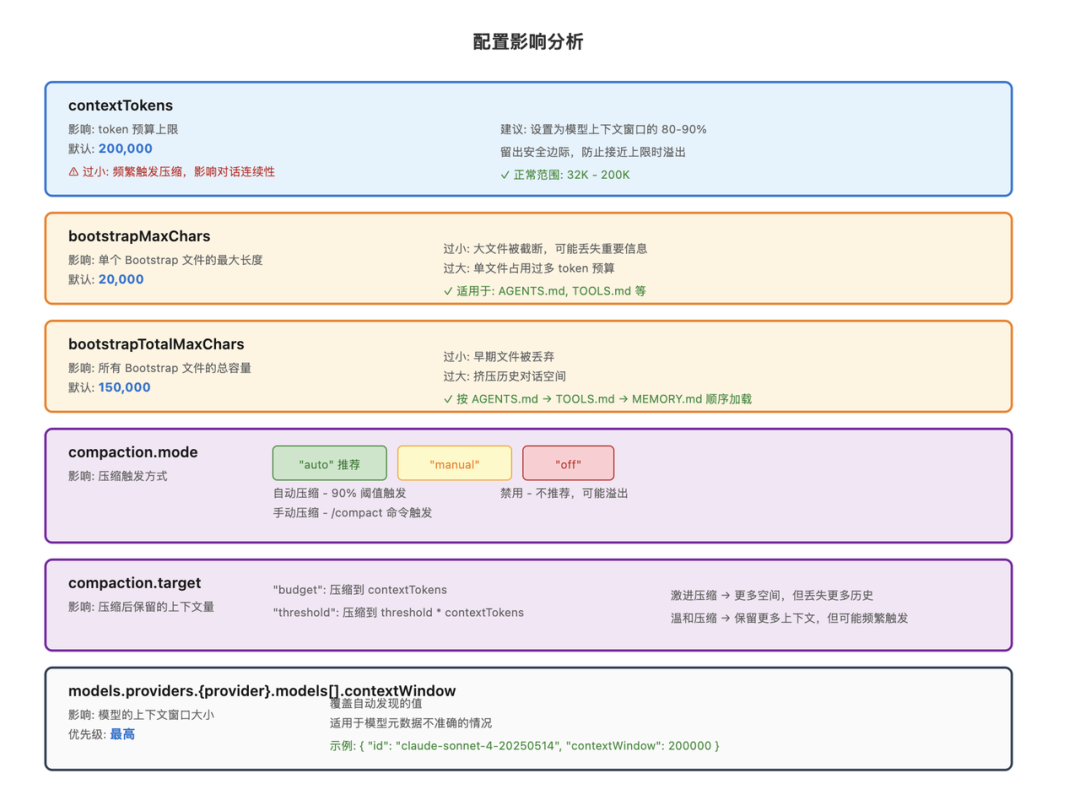
常用配置项:
contextTokens:上下文 token 预算bootstrapMaxChars:单个 Bootstrap 文件字符上限bootstrapTotalMaxChars:Bootstrap 总字符上限compaction.mode:压缩模式(auto/manual/off)compaction.target:压缩目标(budget/threshold)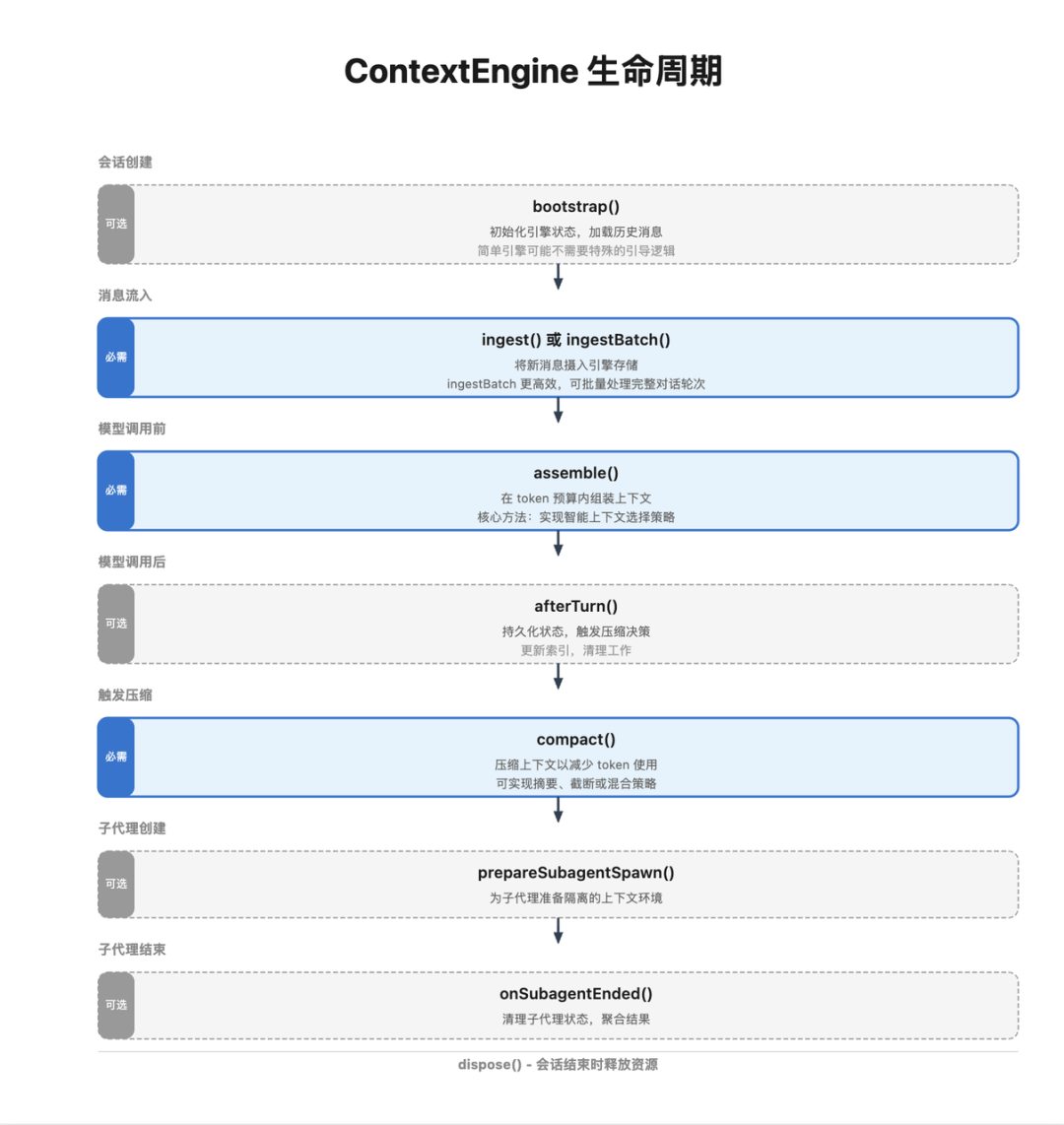
工程实践建议:
OpenClaw 的核心价值不是“能聊天”,而是把上下文作为工程系统来治理:有预算、有策略、有保护、有扩展接口。
本质上,它在做一件事:用有限 token,把模型最该看到的信息稳定地组织出来,并在长周期运行中保持可控与可演进。

© 2020 - 2024 潘深练个人网站 · 豫ICP备2020034308号-1